A Bridge on Economic Issues between China and the World



 Facebook
Facebook  Twitter
Twitter  Instagram
Instagram WeChat
WeChat  Email
Email Data-Intensive Innovation and the State: Understanding China’s AI Leadership

China has become a world leader in the development of artificial intelligence (AI), a data-intensive technology with the potential to transform the global economy. We argue that the Chinese state’s collection of data and provision of data to commercial firms contribute to China’s AI leadership. We provide supportive evidence from China’s facial recognition AI sector and develop a macroeconomic model that illustrates how the Chinese state's surveillance interest aligns with promoting AI innovation, but potentially at the expense of privacy.

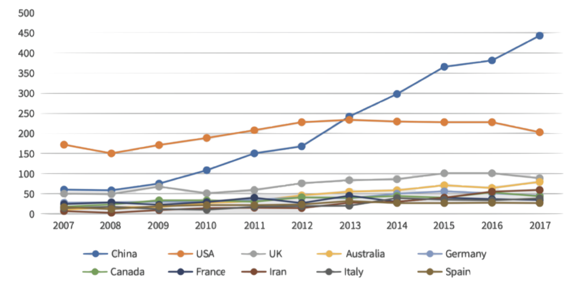
AI innovation has the potential to transform the global economy (Agrawal et al., 2019). In the last decade China has emerged as a global leader in AI innovation, overtaking other nations in highly cited AI research and dominating recent facial recognition competitions organized by the US government’s National Institute of Standards and Technology (see Figure 1). What explains China’s success in AI innovation, and what shapes innovation in data-intensive technology like AI and machine learning?
Figure 1
(a) Top-cited AI research
(b) Top facial recognition AI developers
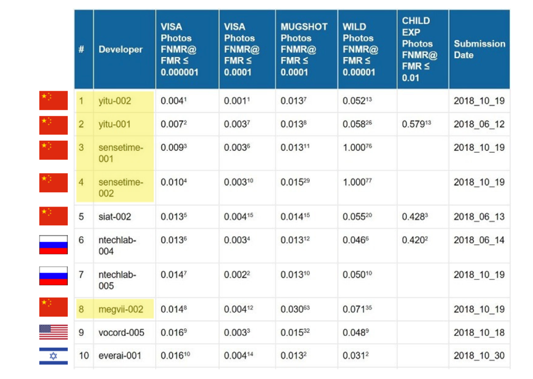
Note: Panel (a) shows highly cited research in AI over time for selected countries. Source: China AI Development Report, 2018. Panel (b) shows Face Recognition Vendor Test (FRVT) rankings of top facial recognition algorithms, based on the time required to achieve a given level of accuracy in detecting faces from photos. Source: National Institute of Standards and Technology (NIST).
We argue in a recent working paper, “Data-Intensive Innovation and the State: Evidence from AI Firms in China,” that the state’s collection of data and provision of data to commercial firms can play a crucial role in shaping AI innovation and contributes to China’s AI leadership. We highlight two key features of data: first, states—especially the Chinese state—possess it in massive quantities. For example, public security agencies possess data collected from security cameras; public health agencies collect data on disease. Second, data can be shared across uses: for example, the same state data that can train AI algorithms for the production of government software can be used to train commercial software algorithms.
These two features of data generate the possibility of economies of scope from government data. Consider a software firm that uses government surveillance data to identify faces and make predictions regarding potential criminal acts. The very same data might be used to identify the faces of shoppers in stores and make predictions regarding their favored products. Firms producing software for the state—and thus receiving access to government data—might therefore become more productive in the development of both new government products and new commercial products.
We test for the existence of economies of scope in the context of Chinese facial recognition AI firms that receive access to government data upon winning a contract to provide government software. This setting is one in which the state has a strong interest in data collection (via public surveillance) for security purposes, and in which private firms provide data analysis services in the form of facial recognition software. It is also a setting in which the state’s identified and identifiable individual data can be of great value in commercial applications.
We first collect data on the universe of Chinese facial recognition AI firms and match these firms to the universe of Chinese government procurement contracts. We then match the Chinese facial recognition AI firms to the software products they release. We use neural network techniques to classify all AI software products according to their intended market, whether government or commercial.
We use a triple differences design to estimate the effect of access to greater amounts of government data on facial recognition AI firms’ subsequent software development. Specifically, we compare firms’ software releases before and after they receive their first government contract from a public security agency (e.g., a contract to process the agency’s surveillance data using the firm’s facial recognition software), controlling for firm and time-period fixed effects. To help pin down the importance of access to government data rather than other benefits of government contracts (such as capital, reputation, market signal, and political connections), we exploit variation in the type of contract: data-rich or data-scarce. We identify contracts that are likely to be especially rich in data as those with public security agencies possessing greater surveillance capacity, which we measure using prefectural government contracts for high resolution surveillance cameras. Thus, our proxy for a data-rich contract is one from a public security agency located in a prefecture with above-median surveillance capacity at the time the contract was awarded, whereas a data-scarce contract is one from a public security agency located in a prefecture with below-median surveillance capacity.
Figure 2
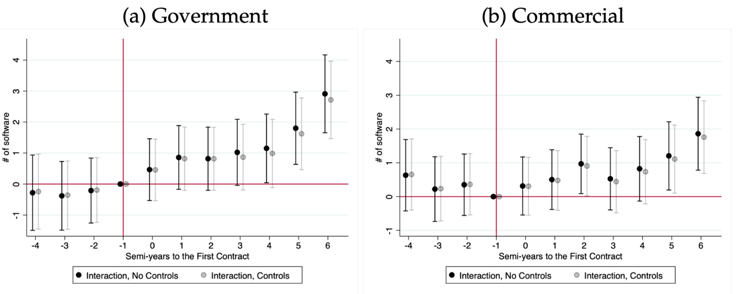
Note: Differential software development intended for government (left column) or for commercial uses (right column), resulting from data-rich contracts, relative to data-scarce contracts, controlling for firm and time-period fixed effects. Horizontal axis measures the semi-years to the first government contract. Data-rich contracts are defined as public security contracts in prefectures with above-median surveillance capacity. Translucent lines/markers additionally interact pre-contract firm characteristics with a full set of time-period fixed effects. Whiskers indicate the 95% confidence intervals.
We find that receipt of a data-rich contract differentially increases both government and commercial software production relative to receipt of a data-scarce contract. As shown in Figure 2 (darker dots), in the three years after the receipt of a contract, data-rich contracts generate an additional three government software products (above the effects of a data-scarce contract), and an additional two commercial software products. We find no evidence of pre-contract differences in software production levels or trends, which one would expect if firms selected into data-rich government contracts based on their potential productivity. Moreover, the inclusion of controls for time-varying effects of firms’ pre-contract characteristics does not affect our findings (as shown in lighter dots in Figure 2). Our evidence is thus consistent with the presence of economies of scope, reflecting crowding-in rather than crowding-out.
A range of corroborating evidence indicates that access to government data contributes to product innovation. First, we observe lower bids (even controlling for firm fixed effects) for data-rich contracts, as well as more bidders overall. Second, we find that production of non-AI, data-complementary software (e.g., software supporting data storage and transmission) significantly, and differentially, increases after firms receive data-rich public security contracts. Finally, we find that firms that produce video facial recognition AI software for the government—which requires access to particularly large amounts of data—exhibit differentially large increases in data-complementary software production and greater commercial and government AI software production, too.
Significant microeconomic consequences of economies of scope arising from government data do not necessarily imply that provision of government data would promote aggregate data-intensive innovation, or increase welfare. To examine the macroeconomic implications of government data access, we develop a directed technical change model, building on Acemoglu (2002). We show that when commercial software and non-software goods are sufficiently substitutable, an increase in government data provided to firms will bias the direction of private innovation towards data-intensive software and increase the economy’s long-run growth rate.
Taken together, our empirical results and model suggest that the alignment between data-intensive innovation and the Chinese state’s surveillance interests can help explain China’s rise to preeminence in AI. Greater surveillance and development of government AI software will not only increase the state’s political control, but also produce the government data (as a by-product) that fuels data-intensive innovation. These results show that surveillance states’ preferences for monitoring and controlling their population may result in an inherent advantage in data-intensive innovation by expanding surveillance spending and the provision of government data.
Importantly, the normative implications of greater data-intensive innovation in surveillance states are complex. Higher economic growth potentially comes at a significant welfare cost to citizens for at least two reasons. First, innovation and surveillance crowd out resources from consumption, given the aggregate resource constraints. Thus, citizen welfare increases only if economies of scope are sufficiently strong to increase the growth rate enough to overcome such crowding-out. Second, citizen preferences regarding data collection can drive a wedge between growth and welfare: if data collection comes at the expense of privacy, growth rates might increase as welfare falls.
[Martin Beraja is the Pentti Kouri Career Development Assistant Professor of Economics at the Massachusetts Institute of Technology (MIT); David Y. Yang is an Assistant Professor of Economics at Harvard University; Noam Yuchtman is a Professor of Management and British Academy Global Professor at the LSE.]
References
Acemoglu, Daron. 2002. “Directed Technical Change,” Review of Economic Studies, 69 (4), 781–809.
Agrawal, Ajay, Joshua Gans, and Avi Goldfarb, eds, The Economics of Artificial Intelligence: An Agenda, University of Chicago Press, 2019.
Beraja, Martin, David Y. Yang, Noam Yuchtman. 2020. “Data-Intensive Innovation and the State: Evidence from AI Firms in China,” NBER Working paper no. 27723.

Latest
Most Popular
- VoxChina Covid-19 Forum (Second Edition): China’s Post-Lockdown Economic Recovery VoxChina, Apr 18, 2020
- China’s Joint Venture Policy and the International Transfer of Technology Kun Jiang, Wolfgang Keller, Larry D. Qiu, William Ridley, Feb 06, 2019
- China’s Great Housing Boom Kaiji Chen, Yi Wen, Oct 11, 2017
- Wealth Redistribution in the Chinese Stock Market: the Role of Bubbles and Crashes Li An, Jiangze Bian, Dong Lou, Donghui Shi, Jul 01, 2020
- The Dark Side of the Chinese Fiscal Stimulus: Evidence from Local Government Debt Yi Huang, Marco Pagano, Ugo Panizza, Jun 28, 2017
- What Is Special about China’s Housing Boom? Edward L. Glaeser, Wei Huang, Yueran Ma, Andrei Shleifer, Jun 20, 2017
- Privatization and Productivity in China Yuyu Chen, Mitsuru Igami, Masayuki Sawada, Mo Xiao, Jan 31, 2018
- How did China Move Up the Global Value Chains? Hiau Looi Kee, Heiwai Tang, Aug 30, 2017
- Evaluating Risk across Chinese Housing Markets Yongheng Deng, Joseph Gyourko, Jing Wu, Aug 02, 2017
- China’s Shadow Banking Sector: Wealth Management Products and Issuing Banks Viral V. Acharya, Jun Qian, Zhishu Yang, Aug 09, 2017


